Neo4j是由Java实现的开源NoSQL图数据库。自2003年开始研发,直到2007年正式发布第一版。
文档:neo4j.com/docs
安装参考博文:【CSDN】neo4j 安装详细步骤及案例
Hyplus目录
1 图数据库概述
图数据库(Graph Database)是基于图论实现的一种NoSQL数据库。它的数据存储结构和数据的查询方式都是以图论为基础的。图论中图的基本元素为节点和边,在图数据库中对应的就是节点和关系。
1.1 发展历程
1960年代中期:Navicational数据库的出现,被认为是图数据库的雏形
1960年代后期:数据库以网络模型的存储与组织方式逐渐衍生出图数据库的概念
90年代初:为了在网站应用中加速索引网页的性能,图数据库有了较大改进
2005年前后:具有ACID特性的图数据库出现,如Neo4j、Oracle Spatial、GraphDB
2010年:具有并行扩展功能的ACID图数据库出现
1.2 与关系数据库的差别
- 数据模型:关系型数据库使用表格来组织和存储数据,每行代表一个记录。而图数据库使用点边结构来存储数据,其中节点代表实体,边代表实体之间的关系
- 存储格式:图数据库将实体存储为节点,将关系存储为边。关系数据库将数据存储在具有行和列的表中,通过JOIN操作进行查询
- 查询语言:关系型数据库通常使用SQL来查询数据。而图数据库使用类似于Cypher、Gremlin等查询语言
- 索引:图数据库通常使用无索引联结,这意味着每个节点都连接到数据库中的每个其他节点,而关系数据库则使用索引指针连接相关数据
1.3 图数据库的优势
- 更擅长处理复杂的关系数据:如社交网络中人与人的关系等。
- 数据结构更灵活:由于采用的是节点和边的数据结构,可以灵活的扩展。
- 具有更高的查询效率:基于图的查询方式,通过遍历点和边来查找数据,大大减少查询的次数。
- 更好地支持非结构化数据:图数据库可以通过图模型来存储半结构化和非结构化数据
- 更好地支持知识图谱和人工智能应用:由于图数据库的图模型可以很好地表示实体之间的关系,因此图数据库可以很好地支持知识图谱的构建和查询。
1.4 Neo4j概述与使用
Neo4j是由Java实现的开源NoSQL图数据库。自2003年开始研发,直到2007年正式发布第一版。Neo4j实现了专业数据库级别的图数据模型的存储。提供了完整的数据库特征,包括ACID事物的支持、集群支持、备份和故障转移等。
下载并解压后,根据README的指引,在安装目录进入终端并执行以下命令:
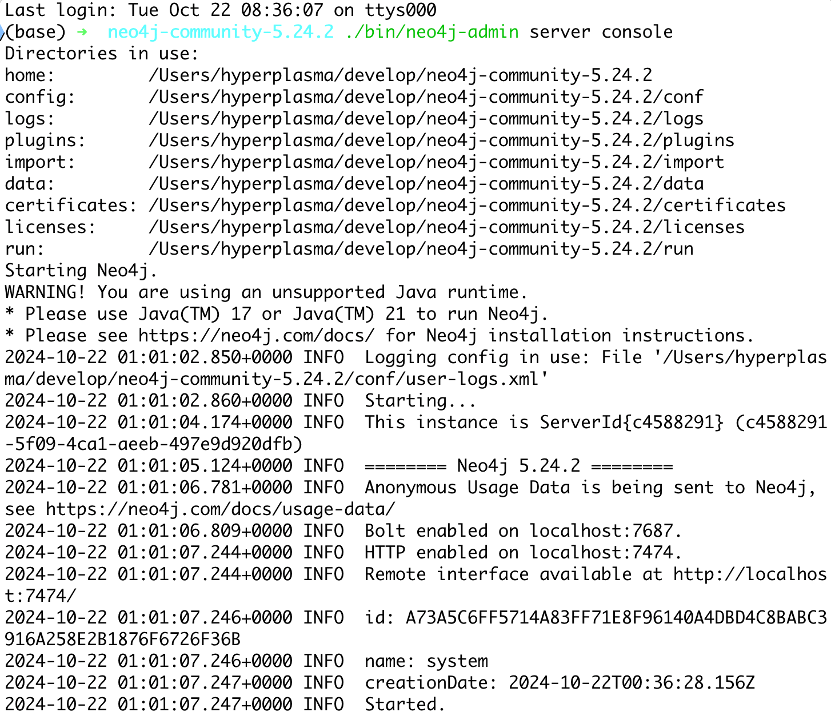
之后在浏览器中操作即可
2 Cypher(CQL)
Cypher是Neo4j图形数据库的查询语言。它是一种声明性模式匹配语言,遵循SQL语法,非常简单且有着十分人性化、可读的格式。
2.1 数据类型
基本数据类型(参考其他编程语言):
- boolean
- byte
- short
- int
- long
- float
- double
- char
- String
NULL值(空值)视为对节点或关系的属性的缺失值或未定义值,判断语句:
IS NULL
IS NOT NULL2.2 常用函数与操作符
| 定制列表功能 | 用法 |
|---|---|
| String | 用于使用String自变量 |
| Aggregation | 用于对CQL查询结果执行一些聚合操作 |
| Relationship | 用于获取关系的细节,如startnode,endnode等 |
IN操作符
IN[<Collection-of-values>][]:集合标记。<Collection-of-values>:由逗号运算符分隔的值的集合
2.3 常用命令
2.3.1 CREATE
CREATE (
<node-name>:<label-name> {
<Property1-name>: <Property1-Value>,
...
<Propertyn-name>: <Propertyn-Value>
}
)<node-name>:节点名称<label-name>:节点标签名称<Property1-name>~<Propertyn-name>:节点的属性的名称<Property1-value>~<Propertyn-value>:节点的属性的值
【例】
CREATE (
dept: Dept {
deptno: 10,
dname: "Accounting",
location: "Hyderabad"
}
)2.3.2 MATCH
MATCH (
<node-name>: <label-name>
)<node-name>:节点名称<label-name>:节点标签名称
2.3.3 RETURN
RETURN
<node-name>.<property1-name>,
........
<node-name>.<propertyn-name><node-name>:节点名称<Property1-name>~<Propertyn-name>:节点的属性的名称
2.3.4 WHERE
WHERE子句语法
WHERE <condition> <boolean-operator> <condition>Condition语法:
<property-name> <comparison-operator> <value><property-name>:节点或属性名称。<comparison-operator>:比较运算符<value>:值
布尔运算符:AND、OR、NOT、XOR
比较运算符:=、<>、<、>、<=、>=
2.3.5 DELETE
DELETE <node-name-list><node-name-list>:要从数据库中删除的节点名称列表
2.3.6 REMOVE
用于删除节点或关系的标签、删除节点或关系的属性
REMOVE <property-name-list><property-name-list>:属性列表,用于永久性地从节点或关系中删除它,其结构如下:
<node-name>.<property1-name>,
<node-name>.<property2-name>,
...
<node-name>.<propertyn-name> 2.3.7 SET
SET <property-name-list><property-name-list>:属性列表,用于执行添加或更新操作以满足要求(结构同上)<node-label-name>:节点的标签名称<property-name>:节点的属性名称
2.3.8 ORDER BY
ORDER BY <property-name-list> [DESC]DESC:降序排列<property-name-list>:属性列表,用于执行添加或更新操作以满足要求(结构同上)<node-label-name>:节点的标签名称<property-name>:节点的属性名称
2.3.9 LIMIT、SKIP
LIMIT <number>
SKIP <number>2.3.10 UNION
<MATCH Command1>
UNION [ALL]
<MATCH Command2><MATCH Command1>、<MATCH Command2>:CQL MATCH命令,由UNION子句使用ALL:返回重复的行
2.3.11 MERGE
MERGE命令是CREATE命令和MATCH命令的组合,它在图中搜索给定的模式,如果存在则返回结果,如果不存在,则创建新的节点/关系并返回结果
MERGE (
<node-name>: <label-name> {
<property1-name>: <Property1-value>
......
<propertyn-name>: <Propertyn-value>
}
)<node-name>:节点名称。<label-name>:节点标签名称。<property-name>:节点或关系的属性名称<property-value>:节点或关系的属性值
《Neo4j图数据库简介》有5条评论