本文围绕数学建模中评价决策类方法展开,介绍了多种常用模型及其实现步骤。层次分析法通过建立递阶层次结构、构造判断矩阵及一致性检验等步骤求得权重,并提供了Python实现。TOPSIS法和熵权法通过标准化和得分计算方法进行评估。模糊综合评价涉及模糊集合的基本理论和应用实例,灰色关联分析(GRA)则侧重于母序列与子序列的数据关系。主成分分析(PCA)帮助探究多指标关系与特征选择。每个方法均包含相应的Python实现示例。
1 层次分析法
怎么能让指标在同一数量级,且保证在同一指标下其差距不变?
-
归一化处理(其一):指标的数组
[a,b,c]归一化处理得到[a/(a+b+c),b/(a+b+c),c/(a+b+c)]。易知a/(a+b+c)+b/(a+b+c)+c/(a+b+c)=1 -
给每一个指标加上权重
1.1 基本概念
面临各种各样的方案,要进行比较、判断、评价、直至最后的决策。这个过程中都是一些主观的因素,这些因素可能由于个人情况的不同,有相应不同的比重,所以这样的主观因素给数学方法的解决带来了很多的不便。
层次分析法(Analytic HierarchyProcess,AHP)是对一些较为复杂、较为模糊的问题作出决策的简易方法,它特别适用于那些难于完全定量分析的问题。
1.2 模型原理
运用层次分析法建模,大体上可按下面四个步骤进行:
1、建立递阶层次结构模型
2、构造出各层次中的所有判断矩阵
3、一致性检验
4、求权重后进行评价
1.2.1 建立递阶层次结构模型
应用AHP分析决策问题时,首先要把问题条理化、层次化,构造出一个有层次的结构模型。在这个模型下,复杂问题被分解为元素的组成部分。这些元素又按其属性及关系形成若干层次。上一层次的元素作为准则对下一层次有关元素起支配作用。这些层次可以分为三类:
- 最高层:这一层次中只有一个元素,一般它是分析问题的预定目标或理想结果,因此也称为目标层。
- 中间层:这一层次中包含了为实现目标所涉及的中间环节,它可以由若干个层次组成,包括所需考虑的准则、子准则,因此也称为准则层。
- 最底层:这一层次包括了为实现目标可供选择的各种措施、决策方案等,因此也称为措施层或方案层。

1.2.2 构造判断矩阵
依次对指标的重要性进行两两比较,构造判断矩阵,从而科学求出权重。矩阵中元素a_{ij}的意义为第i个指标相对第j个指标的重要程度。
标度与含义如下表所示(例:若C1跟C2比明显重要,则重要性为5,反过来C2跟C1比的重要性即为1/5)
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同样重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2, 4, 6, 8 | 上述两相邻判断的中值 |
若矩阵中每个元素满足
a_{ij}>0且满足
a_{ij}\cdot a_{ji}=1则称该矩阵为正互反矩阵。在层次分析法中构造的判断矩阵均为正互反矩阵。
1.2.3 一致性检验
1.2.3.1 一致矩阵
因两两比较的过程中忽略了其他因素,导致最后的结果可能出现矛盾,因此需要一致性检验。由a_{ij}=\frac{i的重要程度}{j的重要程度},a_{ik}=\frac{i的重要程度}{k的重要程度},a_{kj}=\frac{k的重要程度}{j的重要程度}易得
a_{ij}=a_{ik}\cdot a_{kj}且矩阵各行(列)成倍数关系,即
[a_{i1},a_{i2},\cdots,a_{in}]=k_i[a_{11},a_{12},\cdots,a_{1n}]满足这些条件的正互反矩阵为一致矩阵,不会出现矛盾的情况。
【证】一致矩阵满足上述4个条件
引理:A为n阶方阵,且r(A)=1,则A有一个特征值为\text{tr}(A),其余特征值均为0
因为一致矩阵的各行成比例且不是零矩阵,所以一致矩阵的秩一定为1
由引理知,一致矩阵有一个特征值为n,其余特征值均为
易得,特征值为n时,对应的特征向量正好为k[\frac{1}{a_{11}},\frac{1}{a_{12}},\cdots,\frac{1}{a_{1n}}]^{\text{T}}\ (k≠0)
1.2.3.2 检验步骤
由1.4.1证得引理:n阶正互反矩阵A为一致矩阵时,当且仅当最大特征值\lambda_{\max}=n。且当正互反矩阵A非一致时,一定满足\lambda_{\max}>n,判断矩阵越不一致时,最大特征与n相差就越大
一致性检验即为检验构造的判断矩阵和一致矩阵是否有太大差别。
(1)计算一致性指标CI
CI=\frac{\lambda_{\max}-n}{n-1}(2)查表得对应的平均随机一致性指标RI(只需会查表即可。指标个数n一般不超过10,若大于10则可考虑建立二级指标体系,或使用模糊综合评价模型)
\begin{array}{c}
n & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \\
RI & 0 & 0 & 0.52 & 0.89 & 1.12 & 1.26 & 1.36 & 1.41 & 1.46 & 1.49
\end{array}(3)计算一致性比例CR,差距过大时需要修改判断矩阵(如交换元素等)
CR=\frac{CI}{RI}
\left\{\begin{matrix}
=0 & 矩阵即为一致矩阵 \\
<0.1 & 差距不大,判断矩阵一致 \\
≥0.1 & 差距过大,判断矩阵不一致
\end{matrix}\right.1.2.4 求权重
1.2.4.1 算术平均法
方法如下:
(1)将判断矩阵按照列归一化(每一个元素除以其所在列的和)
(2)将归一化的各列相加(按行求和)
(3)将相加后得到的向量中每个元素除以n,即可得到权重向量
对于判断矩阵A=(a_{ij})_{n\times n},用算术平均法求得的权重向量为
w_i=\frac 1n\sum\limits_{j=1}^n \frac{a_{ij}}{\sum\limits_{k=1}^n a_{kj}}\ (i=1,2,\cdots,n)1.2.4.2 几何平均法
方法如下:
(1)将判断矩阵的元素按照行相乘得到一个新的列向量
(2)将新的向量的每个分量开n次方
(3)对该列向量进行归一化即可得到权重向量
对于判断矩阵A=(a_{ij})_{n\times n},用几何平均法求得的权重向量为
w_i=\frac{(\prod\limits_{j=1}^n a_{ij})^{\frac1n}}{\sum\limits_{k=1}^n (\prod\limits_{j=1}^n a_{kj})^{\frac1n}}\ (i=1,2,\cdots,n)1.2.4.3 特征值法
由1.4.1证得,一致矩阵有一个特征值为n,其余特征值均为。并且易得特征值为n时,对应的特征向量正好为k[\frac{1}{a_{11}},\frac{1}{a_{12}},\cdots,\frac{1}{a_{1n}}]^{\text{T}}\ (k≠0)
假设所得的判断矩阵一致性可以接受,则可仿照一致矩阵权重的求法来求取权重:
(1)求出判断矩阵A的最大特征值及其对应的特征向量
(2)对求出的特征向量进行归一化,即可得到权重
1.3 Python实现
import numpy as np
# 定义矩阵A
A = np.array([[1, 2, 3, 5], [1/2, 1, 1/2, 2], [1/3, 2, 1, 2], [1/5, 1/2, 1/2, 1]])
n = A.shape[0] # 获取A的行数(即形状参数的第1维)一致性检验
# 求最大特征值及对应的特征向量
eig_values, eig_vectors = np.linalg.eig(A) # 返回特征值和特征向量
max_eig = max(eig_values) # 返回最大特征值
CI = (max_eig - n) / (n - 1)
RI = [0, 0.0001, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41, 1.46, 1.49, 1.52, 1.54, 1.56, 1.58, 1.59]
# 此处RI最多支持n = 15
# 当n=2时,一定为一致矩阵(CI=0),但为避免分母为0,此处将第2个元素改为一个极小的正数
CR = CI / RI[n - 1]
print("一致性指标CI =", CI)
print("一致性比例CR =", CR)
if CR < 0.10:
print("CR < 0.10,判断矩阵A的一致性可以接受")
else:
print("CT >= 0.10,该判断矩阵A需进行修改")一致性指标CI = (0.03761001273071714+0j)
一致性比例CR = (0.0422584412704687+0j)
CR < 0.10,判断矩阵A的一致性可以接受算术平均法求权重
# 计算每列的和(沿轴0)
sum_A = np.sum(A, axis=0)
# 归一化:二维数组除以一维数组,会自动将一维数组扩展为与二维数组相同的形状,然后进行按元素除法运算
Stand_A = A / sum_A
# 各列相加到同一行(沿轴1)
sum_r_A = np.sum(Stand_A, axis=1)
# 计算权重向量
weights = sum_r_A / n
print(weights)[0.48885991 0.18192996 0.2318927 0.09731744]几何平均法求权重
# 将A中每一行元素相乘得到一列向量
prod_A = np.prod(A, axis=1)
# 将新向量的诶个分量开n次方根(等价于1/n次方)
prod_n_A = np.power(prod_A, 1/n)
# 归一化
re_prod_A = prod_n_A / np.sum(prod_n_A)
print(re_prod_A)[0.49492567 0.17782883 0.22724501 0.1000005 ]特征值法求权重
# 找出最大特征值的索引
max_index = np.argmax(eig_values)
# 找出对应的特征向量
max_vector = eig_vectors[:, max_index]
# 对特征向量进行归一化处理,得到权重
weights = max_vector / np.sum(max_vector)
print(weights)[0.4933895 +0.j 0.17884562+0.j 0.230339 +0.j 0.09742588+0.j]2 TOPSIS法
距离最好点最近或者距离最差点最远的的就是综合条件最好的
2.1 基本概念
TOPSIS(Technique for Order Preference by
Similarity to an Ideal Solution,逼近理想解排序法,优劣解距离法)是一种常用的综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
TOPSIS法引入了两个基本概念:
- 理想解:设想的最优的解(方案),它的各个属性值都达到各备选方案中的最好的值
- 负理想解:设想的最劣的解(方案),它的各个属性值都达到各备选方案中的最坏的值。
方案排序的规则是把各备选方案与理想解和负理想解做比较,若其中有一个方案最接近理想解,而同时又远离负理想解,则该方案是备选方案中最好的方案。TOPSIS通过最接近理想解且最远离负理想解来确定最优选择。

模型原理:TOPSIS法是一种理想目标相似性的顺序选优技术,在多目标决策分析中是一种非常有效的方法。它通过归一化后(去量纲化)的数据规范化矩阵,找出多个目标中最优目标和最劣目标(分别用理归想一解化和反理想解表示),分别计算各评价目标与理想解和反理想解的距离,获得各目标与理想解的贴近度,按理想解贴近度的大小排序,以此作为评价目标优劣的依据。贴近度取值在0~1之间,该值愈接近1,表示相应的评价目标越接近最优水平;反之,该值愈接近0,表示评价目标越接近最劣水平。
2.2 模型原理
TOPSIS法的基本步骤如下所示:
(1)将原始矩阵正向化:即为将所有的指标类型统一转化为极大型指标(即越大越好)
(2)正向矩阵标准化:方法很多,其主要目的为去除量纲的影响,保证不同评价指标在同一数量级,且数据大小排序不变
(3)计算得分并归一化(其中S_i为得分,D_i^+为评价对象与最大值的距离,D_i^-为评价对象与最小值的距离)
S_i=\frac{D_i^-}{D_i^++D_i^-}2.2.1 正向化
将原始矩阵正向化,即为将所有指标类型统一转化为极大型指标\tilde{x}。
| 指标名称 | 指标特点 | 例子 |
|---|---|---|
| 极大型(效益型)指标 | 越大(多)越好 | 颜值、成绩、GDP增速 |
| 极小型(成本型)指标 | 越小(少)越好 | 脾气、费用、坏品率、污染程度 |
| 中间型指标 | 越接近某个值越好 | 身高、水质量评估时的PI值 |
| 区间型指标 | 落在某个区间最好 | 体重、体温 |
极小型指标正向化(x为指标值,x_\text{max}为指标最大值):
\tilde{x} = x_\text{max} - x中间型指标正向化(\{x_i\}为一组中间型序列,最优值为x_{\text{best}}):
M=\max\{|x_i-x_\text{best}|\}\\ \tilde{x}_i=1-\frac{|x_i-x_\text{best}|}{M}区间型指标正向化(\{x_i\}为一组区间型序列,最佳区间为[a,b]):
M=\max\{a-\min\{x_i\},\max\{x_i\}-b\}\\ \tilde{x}=\left\{\begin{matrix}
1-\frac{a-x_i}{M}&,\ x_i < a \\
1&, \ a≤x_i≤b\\
1-\frac{x_i-b}{M}&,\ x_i>b
\end{matrix}\right.2.2.2 标准化
标准化的目的是消除不同指标量纲的影响。
设由n个要评价的对象、m个评价指标(已正向化)构成的正向化矩阵为X=(x_{ij})_{n\times m},其标准化矩阵为Z=(z_{ij})_{n\times m}。则Z中的每一个元素为X的每一个元素/√其所在列的元素的平方和,即
z_{ij}=\frac{x_{ij}}{\sqrt{\sum\limits_{i=1}^n x_{ij}^2}}标准化后,还需给不同指标加上权重,采用的权重确定方法有层次分析法(详见1.2)、熵权法(详见3.2.1)、Delphi法、对数最小二乘法等。此处主观设置各个指标的权重相同。
2.2.3 计算得分、归一化
由2.2.2得,标准化矩阵Z=(z_{ij})_{n\times m}
定义最大值
Z^+=(Z_1^+,Z_2
^+,\cdots,Z_m^+)=(\max\{z_{11},z_{21},\cdots,z_{n1}\},\cdots,\max\{z_{1m},z_{2m},\cdots,z_{nm}\})定义最小值
Z^-=(Z_1^-,Z_2
^-,\cdots,Z_m^-)=(\min\{z_{11},z_{21},\cdots,z_{n1}\},\cdots,\min\{z_{1m},z_{2m},\cdots,z_{nm}\})定义第i\ (i=1,2,\cdots,n)个评价对象与最大值的距离
D_i^+=\sqrt{\sum\limits_{j=1}^m(Z_j^+-z_{ij})}定义第i\ (i=1,2,\cdots,n)个评价对象与最小值的距离
D_i^-=\sqrt{\sum\limits_{j=1}^m(Z_j^--z_{ij})}由此可计算得第i\ (i=1,2,\cdots,n)个评价对象未归一化的得分
S_i=\frac{D_i^-}{D_i^++D_i^-}显然0≤S_i≤1,且S_i越大D_i^+越小,即越接近最大值。
可以将得分归一化并换算成百分制
\tilde{S}_i=\frac{S_i}{\sum\limits_{i=1}^nS_i}\times 1002.3 Python实现
具体案例及优化见5.3.2
import numpy as np
# 参评对象、指标的个数
n = 3
m = 4
# 每个指标的类型,列表长度需为m(1:极大型,2:极小型,3:中间型,4:区间型)
kind = [1, 2, 3, 4]
# 矩阵,形状为(n, m)
A = np.array([9, 10, 175, 120, 8, 7, 164, 80, 6, 3, 157, 90]).reshape(n, m)
best_A = 165 # 若为中间型(类型3),还需设置最优值
low_A = 90 # 若为区间型(类型4),还需设置上下限
high_A = 100
print(A)[[ 9 10 175 120]
[ 8 7 164 80]
[ 6 3 157 90]]原始矩阵正向化
# 极小值指标转化为极大值指标
def min_to_max(x, max_x):
x = list(x) # 将输入的指标数据转换为列表
res = [[(max_x - e)] for e in x] # 计算最大值与每个指标元素的差
return np.array(res) # 将列表转换为numpy数组并返回
# 中间型指标转化为极大值指标
def mid_to_max(x, best_x):
x = list(x)
h = [abs(e - best_x) for e in x] # 计算每个指标元素与最优值的绝对差
M = max(h) # 找到最大的差值
if M == 0:
M = 1 # 防止最大差值为0的情况
res = [[1 - e / M] for e in h] # 计算每个差值占最大差值的比例,并从1中减去,得到新指标值
return np.array(res)
# 区间型指标转化为极大值指标
def reg_to_max(x, low_x, high_x):
x = list(x)
M = max(low_x - min(x), max(x) - high_x) # 计算指标值超出区间的最大距离
if M == 0:
M = 1 # 防止最大距离为0的情况
res = []
for i in range(len(x)):
if x[i] < low_x:
res.append([(1 - (low_x - x[i]) / M)]) # 如果指标值小于下限,则计算其与下限的距离比例
elif x[i] > high_x:
res.append([1 - (x[i] - high_x) / M]) # 如果指标值大于上限,则计算其与上限的距离比例
else:
res.append([1]) # 如果指标值在区间内,则直接取为1
return np.array(res)
# 统一指标类型,将所有指标转化为极大型指标
X = np.zeros((n, 1))
for i in range(m):
if kind[i] == 1:
v = np.array(A[:, i])
elif kind[i] == 2:
max_A = max(A[:, i])
v = min_to_max(A[:, i], max_A)
elif kind[i] == 3:
v = mid_to_max(A[:, i], best_A)
else:
v = reg_to_max(A[:, i], low_A, high_A)
if i == 0:
X = v.reshape(-1, 1) # 若为第1个指标,直接替换X数组
else:
X = np.hstack([X, v.reshape(-1, 1)]) # 若非第1个指标,则将该指标列拼接到X数组上
print("统一指标后的矩阵为:\n{}".format(X)) # 打印处理后的矩阵X统一指标后的矩阵为:
[[9. 0. 0. 0. ]
[8. 3. 0.9 0.5]
[6. 7. 0.2 1. ]]正向矩阵标准化
# 正向矩阵标准化
X = X.astype('float') # 确保X矩阵的数据类型为浮点数
for j in range(m):
# %?%>
X[:, j] = X[:, j] / np.sqrt(sum(X[:, j] ** 2)) # 对每一列数据进行归一化处理,即除以该列的欧几里得范数
print("标准化后的矩阵为:\n{}".format(X))标准化后的矩阵为:
[[0.66896473 0. 0. 0. ]
[0.59463532 0.3939193 0.97618706 0.4472136 ]
[0.44597649 0.91914503 0.21693046 0.89442719]]计算得分、归一化
# 最大值与最小值距离的计算
max_x = np.max(X, axis=0) # 每个指标的最大值
min_x = np.min(X, axis=0) # 每个指标的最小值
d_to_max = np.sqrt(np.sum(np.square((X - np.tile(max_x, (n, 1)))), axis=1)) # 计算每个参评对象与最优情况的距离d+
d_to_min = np.sqrt(np.sum(np.square((X - np.tile(min_x, (n, 1)))), axis=1)) # 计算每个参评对象与最劣情况的距离d-
print("每个指标的最大值:", max_x)
print("每个指标的最小值:", min_x)
print("d+向量:", d_to_max)
print("d-向量:", d_to_min)每个指标的最大值: [0.66896473 0.91914503 0.97618706 0.89442719]
每个指标的最小值: [0.44597649 0. 0. 0. ]
d+向量: [1.61175952 0.69382053 0.79132442]
d-向量: [0.22298824 1.15334862 1.30072534]# 计算每个参评对象的得分排名
s = d_to_min / (d_to_max + d_to_min) # 根据d+和d-计算得分s,其中s接近于1表示较优,接近于0表示较劣
scores = 100 * s / sum(s) # 将得分s转换为百分制,便于比较
for i in range(len(scores)):
print(f"第{i + 1}个参评对象的百分制得分: {scores[i]}")第1个参评对象的百分制得分: 8.886366735657832
第2个参评对象的百分制得分: 45.653341055701134
第3个参评对象的百分制得分: 45.460292208641033 熵权法
3.1 基本概念
按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量。根据信息熵的定义,对于某项指标,可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大,该指标对综合评价的影响(即权重)就越大。如果某项指标的值全部相等,则该指标在综合评价中不起作用。因此可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
熵权法是一种客观的赋权方法,它可以靠数据本身得出权重。指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低。
3.2 模型原理
算法步骤:
(1)数据标准化
(2)计算概率矩阵
(3)计算熵权
3.2.1 标准化
与2.2.2相同,对于由n个要评价的对象、m个评价指标(已正向化)构成的指标矩阵X=(x_{ij})_{n\times m},其标准矩阵为Z=(z_{ij})_{n\times m}。则标准矩阵中的每一个元素为
z_{ij}=\frac{x_{ij}}{\sqrt{\sum\limits_{i=1}^n x_{ij}^2}}若指标矩阵X中存在负数,则标准化矩阵为
\tilde{Z}=\frac{x-\min\{x_{ij},x_{2j},\cdots,x_{nj}\}}{\max\{x_{1j},x_{2j},\cdots,x_{nj}\}-\min\{x_{ij},x_{2j},\cdots,x_{nj}\}}3.2.2 计算概率矩阵
概率矩阵P:元素p_{ij}表示第j项指标下第i
p_{ij}=\frac{\tilde{z}_{ij}}{\sum\limits_{i=1}^n\tilde{z}_{ij}} 3.2.3 计算熵权
对于第j个指标,信息熵的计算公式为
e_j=-\frac{1}{\ln n}\sum\limits_{i=1}^n p_{ij} \ln(p_{ij})\ (j=1,2,\cdots,m)易知,当p_{1j}=p_{2j}=\cdots=p_{nj}=\frac1n时信息熵最大,但其信息效用值最小。信息效用值的定义为
d_j=1-e_j此时效用值越大,权重越大。将信息效用值进行归一化,得到熵权
W_j=\frac{d_j}{\sum\limits_{j=1}^m d_j}3.3 Python实现
import numpy as np
# 指标矩阵
X = np.array([9, 0, 0, 0, 8, 3, 0.9, 0.5, 6, 7, 0.2, 1]).reshape(3, 4)
print(X)[[9. 0. 0. 0. ]
[8. 3. 0.9 0.5]
[6. 7. 0.2 1. ]]数据标准化
# 标准化
Z = X / np.sqrt(np.sum(X * X, axis=0))
print(f"标准化矩阵:\n{Z}")标准化矩阵:
[[0.66896473 0. 0. 0. ]
[0.59463532 0.3939193 0.97618706 0.4472136 ]
[0.44597649 0.91914503 0.21693046 0.89442719]]计算概率矩阵、信息熵、信息效用值,最终得出权重
# 计算熵权所需的变量和矩阵初始化
n, m = Z.shape # 获取标准化矩阵的行数和列数
D = np.zeros(m) # 长度为m的信息效用值数组
# 自定义对数函数,用于处理输入数组中的零元素
def my_log(p):
n = len(p) # 获取向量p的长度
ln_p = np.zeros(n) # 创建一个长度为n、元素均为0的新数组
for i in range(n): # 遍历向量p
if p[i] == 0:
ln_p[i] = 0 # 直接np.log(0)会得到-inf,此处规定值为0
else:
ln_p[i] = np.log(p[i]) # 若非0则正常计算
return ln_p
# 计算各个指标的信息效用值
for i in range(m): # 遍历Z的每一列
x = Z[:, i] # 获取Z的第i列,即第i个指标的所有数据
p = x / np.sum(x) # 对第i个指标的数据进行归一化处理,得到概率分布p
# p中可能含有0元素,因此需对p使用自定义对数函数
e = -np.sum(p * my_log(p)) / np.log(n) # 根据熵的定义,计算第i个指标的信息熵
D[i] = 1 - e # 根据信息效用值的定义计算第i个指标的信息效用值
# 根据信息效用值计算各指标的权重
W = D / np.sum(D)
print(f"权重W:\n{W}")权重W:
[0.00856537 0.30716152 0.39326471 0.2910084 ]4 模糊综合评价
模糊是指客观事物差异的中间过渡中的“不分明性”或“亦此亦彼性”。如高个子与矮个子、年轻人与老年人、热水与凉水、环境污染严重与不严重等。在决策中,也有这种模糊的现象,很多事物没有绝对分明和固定不变的界限,例如“好”与“不好”。这些现象很难用经典的数学来描述。
处理现实的数学模型可以分成三大类:第一类是确定性数学模型,即模型的背景具有确定性,对象之间具有必然的关系。第二类是随机性数学模型,即模型的背景具有随机性和偶然性。第三类是模糊性模型,即模型的背景及关系具有模糊性。
4.1 模糊集合论
4.1.1 模糊集合的定义
4.1.1.1 经典集合
集合:具有相同属性的事物的集体,自然数集、实数集、颜色等。
集合的基本属性:
(1)互斥性:若a\in A,\ b\in A,则a≠b
(2)确定性:a\in A,\ a\notin A有且仅有之一发生(非此即彼)
数学上对经典集合的刻画:集合A的特征函数f_A:U\rightarrow\{0,1\},其中U为论域。
4.1.1.2 模糊集合和隶属函数
模糊集合:用来描述模糊性概念的集合,例如美、丑、高、矮、年轻、年长等。
与经典集合相比,模糊集合承认亦此亦彼。
数学上对模糊集合的刻画:对于X上的一个模糊集合A,其隶属函数\mu_A:X\rightarrow[0,1],\ x\rightarrow \mu_A(x),\mu_A(x)称为x对模糊集A的隶属度。记A=\{(x,\mu_A(x))|x\in X\},显然模糊集A完全由隶属函数来刻画,\mu_A(x)=0.5最具模糊性。
【例】要衡量“年轻”的概念A=“年前”,X=(0,150)表示年龄区间。这里不方便直接在0~150之间划分年轻与不年轻,可以设一个隶属函数来进行描述(不唯一)
\mu_A(x)=\left\{\begin{matrix}
1 & \ 0\lt x \lt20\\
\frac{40-x}{20} & 20≤x≤40\\
0 & 40\lt x \lt150
\end{matrix}\right.对于X中的每一个元素,均对应于A中的一个隶属度,隶属于介于[0,1],越大表示越属于这个集合。
4.1.2 模糊集合的表示法
当论域X=\{x_1,x_2,\cdots,x_n\}为有限集时,X上的模糊集A有三种表示形式:
(1)zadeh表示法
A=\sum\limits_{i=1}^n\frac{\mu_A(x_i)}{x_i}(2)序偶表示法
A=\{(x_1,\mu_A(x_1)),(x_2,\mu_A(x_2)),\cdots,(x_n,\mu_A(x_n))\}(3)向量表示法
A=(\mu_A(x_1),\mu_A(x_2),\cdots,\mu_A(x_n))当论域X=\{x_1,x_2,\cdots,x_n\}为无限集时,X上的模糊集A可如下表示:
A=\int\limits_{x\in X}\frac{\mu_A(x)}{x}注:上述的
Σ和+并非求和,仅用于概括集合;\frac{\mu_A(i)}{x_i}也并非分数,仅表示点x_i对模糊集A的隶属度为\mu_A(x_i);\int也不是积分的意思)
【例1】设论域X=\{x_1(140),x_2(150),x_3(160),x_4(170),x_5(180),x_6(190)\}(单位:cm)表示人的身高,X上的一个模糊集A=“高个子”的隶属函数定义为
\mu_A(x)=\frac{x-140}{190-140}则A用上述有限集的三种表示法分别表示为:
(1)zadeh表示法
A=\frac0{x_1}+\frac{0.2}{x_2}+\frac{0.4}{x_3}+\frac{0.6}{x_4}+\frac{0.8}{x_5}+\frac1{x_6}(2)序偶表示法
A=\{(140,0),(150,0.2),(160,0.4),(170,0.6),(180,0.8),(190,1)\}(3)向量表示法
A=(0,0.2,0.4,0.6,0.8,1)【例2】设论域X=[0,1],模糊集A=“年轻”,A的隶属函数定义为
\mu_A(x)=\left\{\begin{matrix}
1 &, \ 0\le x \le25\\
[1+(\frac{x-25}{5})^2]^{-1} &,\ 25\lt x \le 100
\end{matrix}\right.则A用上述无限集的表示法可以表示为:
A=\int_0^{25}\frac1x+\int_{25}^{100}\frac{[1+(\frac{x-25}{5})^2]^{-1}}{x}4.1.3 模糊集合的分类
模糊集合可以分为偏小型、中间型和偏大型(类比TOPSIS中的各种指标类型,详见2.2.1)。
【例】“年轻”是一个偏小型的模糊集合,因为岁数越小,隶属度越大,就越“年轻”;“年老”则是一个偏大型的模糊集合,岁数越大,隶属度越大,越“年老”;而“中年”则是一个中间型集合,岁数只有处在某个中间的范围,隶属度才越大。总结来说,就是考虑“元素”与“隶属度”的关系,再类比一下,就是考虑隶属函数的单调性。
4.1.4 隶属函数的确定 ⭐️
4.1.4.1 模糊统计法
找多个人对同一个模糊概念进行描述,用隶属频率去定义隶属度。
【例】想知道30岁相对于“年轻”的隶属度,可以找n个人问一问,如果其中有m个人认为30岁属于“年轻”的范畴,则m/n就可以用来作为30岁相对于“年轻”的隶属度。n越大就越符合实际情況,也就越准确。
该方法比较符合实际情况,但是往往通过发放问卷或者其他手段进行调查,数学建模比赛时,时间有限,因此仅做介绍,基本不予采用。
4.1.4.2 借助已有的客观尺度
对于某些模糊集合,可以用已有的指标作为元素的隶属度。
【例1】“小康家庭”这一模糊集合可以用恩格尔系数(食品支出总额/家庭总支出)衡量相应的隶属度。显然,家庭越接近小康水平,其恩格尔系数应该越低,则1-恩格尔系数就越大,因此可以把1-恩格尔系数看作家庭相对于“小康家庭”的隶属度。
【例2】对于“质量稳定”这一模糊集合,可以使用正品率衡量隶属度。
注:隶属度应在[0,1]之间,如果找的指标不在该区间内,应进行归一化处理。
4.1.4.3 指派法 ⭐️
指派法是一个主观性比较强的方法,即凭主观意愿,在确定模糊集合的所属分类后,为每个因素指派一个隶属函数,得到元素的隶属度。这是比赛中最常用的方法之一,只需进行选择,便可得到隶属函数。
常用的模糊分布如下图所示:
(WIP)

可见,对于偏小型模糊集合,隶属函数总体上递减,也就是元素的某个特征越大,隶属度越小;对于偏大型集合,隶属函数总体上递增,也就是元素的某个特征越大,隶属度越大;对于中间型集合,隶属函数总体上先递增后递减,中间一部分或是某个点取到最大值。
其他方法:德尔菲法、二元对比排序法、综合
加权法……
4.2 模型原理
4.2.1 基本算法步骤
模糊评价问题的目标为把论域中的对象对应评语集中一个指定的评语,或者将方案作为评语集并选择一个最优的方案。
在模糊综合评价中,引入三个集合:
(1)因素集:评判的因素构成的评价指标体系集合,又称评价指标集。U=\{u_1,u_2,\cdots,u_n\}
(2)评语集:由各种不同决断构成的集合,即为评价的结果。V=\{v_1,v_2,\cdots,v_n\}
(3)权重集:各因素的权重的集合。因素集中各因素的评价中作用不同,需要确定权重,它是因素集U上的模糊向量。判断权重的方法有层次分析法、熵权法、Delphi法等。A=\{a_1,a_2,\cdots,a_n\}
【例】评价一名学生的表现可以如此设置:U=\{专业排名,课外实践,志愿服务,竞赛成绩\}、V=\{优,良,差\}、A=\{0.4,0.2,0.1,0.3\}
模糊综合评价模型:根据因素集的指标(即为隶属度),从评语集中找到一个最适合给定对象的评语,或从评语集中选出一个最恰当的方案。
4.2.2 多层次模糊综合评价模型
mini-batch
(1)给出被评价的对象集合X=\{x_1,x_2,\cdots,x_k\}
(2)确定因素集U=\{u_1,u_2,\cdots,u_n\},若因素众多,则将U按某些属性划分为s个子类U_i=\{u_1^{(i)},u_2^{(i)},\cdots,u_n^{(i)}\},\ i=1,2,\cdots,s,且满足:①\sum\limits_{i=1}^s n_i=n;②\bigcup_{i=1}^{s}U_i=U;③U_i\cap U_j=\emptyset,\ i≠j
(3)确定评语集V=\{v_1,v_2,\cdots,v_m\}
(4)由因素集的一个子集U_i和评语集V,获得一个评价矩阵R_i=(r_{ij}^{(i)})_{n_i \times m}(方法不限,详见4.2.2)
(5)对每一个U_i分别作出综合决策:设U_i中各因素权重的分配(模糊权向量)为A_i=(a_1^{(i)},a_2^{(i)},a_3^{(i)},\cdots,a_{n_i}^{(i)}),其中\sum\limits_{t=1}^{n_i}a_t^{(i)}=1,若R_i为单因素模糊判断矩阵,则得到一级评价向量为B_i=A_i\cdot R_i=(b_{i1},b_{i2},\cdots,b_{im}),\ i=1,2,\cdots,s
(6)将每个U_i视为一个元素(因素),记U=\{U_1,U_2,\cdots,U_s\},则U即成为单因素集,其单因素判断矩阵R=(B_1,B_2,\cdots,B_s)^{\text{T}}=(b_{ij})_{s\times m}。每个U_i反映了U的某种属性,可得其权重分配A=(a_1,a_2,\cdots,a_s)。由此可得二级模糊综合评价模型为B=A\cdot R=(b_1,b_2,\cdots,b_m)
若每个子因素U_i仍有较多元素,可将其再划分,于是有三级或更高级模型。
4.3 典型例题
4.3.1 例1:打分(模糊统计法)
【例1】对企业员工进行考核时,在指标个数较少的考核中可以运用一级模糊综合评判。隶属度通过模糊统计法(打分)来确定。
(1)确定因素集。此处选取U=\{政治表现u_1,工作能力u_2,工作态度u_3,工作成绩u_4\}
(2)确定评语集。此处选取V=\{优秀v_1,良好v_2,一般v_3,较差v_4,差v_5\}
(3)确定各因素的权重。此处选取A=\{0.25,0.2,0.25,0.3\}
(4)确定模糊综合判断矩阵。对于指标u_i,其对各个评语的隶属度为V上的模糊子集,对指标u_i的评判记为R_i=[r_{i1},r_{i2},\cdots,r_{in}],则各指标的模糊综合判断矩阵为R=(r_{ij})_{n\times m},这是一个U\rightarrow V的模糊关系矩阵。
以政治表现u_1为例,r_1=[0.1,0.5,0.4,0,0]表示:参与打分的群众中,10%的人认为该员工政治表现优秀,50%的人认为其政治表现良好等。其他因素同理,最终可构成评价矩阵/模糊综合判断矩阵。
(5)模糊综合评判,进行矩阵合成运算(如下图所示)。可得结果B=A\cdot R为一个行向量,取数值最大的评语作为综合评判结果。

4.3.2 例2:指派隶属函数 ⭐️
【例2】某露天煤矿有五个边坡设计方案,其各项参数根据分析计算结果得到边坡设计方案如下表所示。据勘探,该矿探明储量8800吨,开采总投资不超过8000万元,试做出各方案的优劣排序,选出最佳方案。

(1)可采矿量的隶属函数:因为勘探的储量为8800吨,故可用资源的利用函数作为隶属函数,为\mu_A(x)=\frac{x}{8800}
(2)基建投资的隶属函数:投资约束为8000万元,故隶属函数为\mu_B(x)=1-\frac{x}{8000}(极小型)
(3)采矿成本的隶属函数:根据专家意见,采矿成本a_1≤5.5元/吨位低成本,a_2=8.0万元/吨位高成本,故\mu_C(x)=\left\{\begin{matrix} 1 &,\ 0\le x\le a_1\\ \frac{a_2-x}{a_2-a_1} &,\ a_1\lt x \lt a_2\\ 0 &,\ x≥a_2 \end{matrix}\right.
(4)不稳定费用的隶属函数:\mu_D(x)=1-\frac{x}{200}
(5)净现值的隶属函数:取上限15(百万元)、下限0.5(百万元),采用线性隶属函数,即\mu_E(x)=\frac{x-50}{1500-50}=\frac{x-50}{1450}
(6)根据上述5个隶属函数,将上表中数据代入可得5个方案所对应的不同隶属度(如下表所示)

该表即为单因素评判矩阵R=(r_{ij})_{5\times 5}。根据专家评价,诸因素在决策中占的权重为A=(0.25,0.20,0.20,0.10,0.25)(或通过层次分析法、熵权法等确定权重)
(7)模糊综合评判,进行矩阵合成运算(详见例1)。可得结果B=A\cdot R=(0.7435,0.5919,0.6789,0.3600,0.3905),由此可知:方案1最佳,方案3次之,方案4最差
4.3.3 例3:三级模糊综合评价
【例】对某陶瓷厂生产的6种产品的销售前景进行评判
(1)影响评判对象因素集的选取:从产品情况、销售能力、市场需求三个方面考虑,根据专家评判法,得到评判对象因素集及子因素组成下图(因素后数据表示权重)

(2)备择集V=\{1,2,3,4,5,6\}代表6种不同的陶瓷产品
(3)一级模糊综合评价:“运行费用”下属的三级指标是定量指标,有具体数据,对这些数据归一化(即求出各种产品的该指标与总指标的比重),得到单因素隶属度(如下第1张表所示);其他因素均为定性指标,通过市场调查,把消费者的满意度作为单因素的隶属度(如下第2张表所示)。(两种方法详见4.2.2)


第2张表子类“运输费用”行部分即为影响运输费用的各因素的单因素评价矩阵R_{23};由(1)中图最右侧可得权重分配A_{23}。则运行费用的一级评判为B_{23}=A_{23}\cdot R_{23}=[0.1910,0.1565,0.1595,0.1465,0.1505,0.1960]。之后可以将“运输费用”单独作为一个指标来进行下一级的运算。
(4)二级模糊综合评价:对产品情况、销售能力、市场需求下属的单因素指标进行二级评判(方法与之前相同)。对于产品情况,用同样方式可得R_1,A_1,则二级评判为B_1=A_1\cdot R_1=[0.1410,0.1375,0.1655,0.2215,0.1545,0.1800];对于销售能力,将运行费用的一级评判结果作为其二级评判的单因素评价值(即评判矩阵的某一行),同理可得$$R_2,A_2$$,则其二级评判为$$B_2=A_2\cdot R_2=[0.1508,0.1481,0.1474,0.1636,0.1701,0.2200]$$;对于市场需求,同理可得$$R_3,A_3$$,则其二级评判为$$B_3=A_3\cdot R_3=[0.1545,0.1445,0.1525,0.1620,0.1490,0.2375]$$
(5)三级模糊综合评价:将二级评判结果作为行,组成三级评判单因素评判矩阵R=[B_1,B_2,B_3]^{\text{T}},权重A=[0.40,0.30,0.30],则三级评判为B=A\cdot R=[0.1480,0.1428,0.1562,0.1863,0.1575,0.2093]。由结果可知,产品6得分最高,可加大投资,产品1、2得分较低,应减少投资。
4.4 Python实现
import numpy as np
# 一级模糊综合评判
# 影响运行费用的单因素评价矩阵
R23 = np.array([
[0.18, 0.14, 0.18, 0.14, 0.13, 0.23],
[0.15, 0.20, 0.15, 0.25, 0.10, 0.15],
[0.25, 0.12, 0.13, 0.12, 0.18, 0.20],
[0.16, 0.15, 0.21, 0.11, 0.20, 0.17],
[0.23, 0.18, 0.17, 0.16, 0.15, 0.11],
[0.19, 0.13, 0.12, 0.12, 0.11, 0.33],
[0.17, 0.16, 0.15, 0.08, 0.25, 0.19]
])
# 权重分配
A23 = np.array([0.20, 0.15, 0.10, 0.10, 0.20, 0.15, 0.10])
# 评价结果
B23 = np.dot(A23, R23)
# 二级模糊综合评判
# 产品情况的二级评判
R1 = np.array([
[0.12, 0.18, 0.17, 0.23, 0.13, 0.17],
[0.15, 0.13, 0.18, 0.25, 0.12, 0.17],
[0.14, 0.13, 0.16, 0.18, 0.20, 0.19],
[0.12, 0.14, 0.15, 0.17, 0.19, 0.23],
[0.16, 0.12, 0.13, 0.25, 0.18, 0.16]
])
A1 = np.array([0.15, 0.40, 0.25, 0.10, 0.10])
B1 = np.dot(A1, R1)
# 销售能力的二级评判
R2 = np.array([
[0.13, 0.15, 0.14, 0.18, 0.16, 0.25],
[0.12, 0.16, 0.13, 0.17, 0.19, 0.23],
B23,
[0.14, 0.13, 0.15, 0.16, 0.18, 0.24],
[0.16, 0.15, 0.15, 0.17, 0.18, 0.19]
])
A2 = np.array([0.20, 0.15, 0.25, 0.25, 0.15])
B2 = np.dot(A2, R2)
# 市场需求的二级评判
R3 = np.array([
[0.15, 0.14, 0.13, 0.18, 0.14, 0.26],
[0.16, 0.15, 0.18, 0.14, 0.16, 0.21]
])
A3 = np.array([0.55, 0.45])
B3 = np.dot(A3, R3)
# 三级模糊综合评判
R = np.array([B1, B2, B3])
A = np.array([0.4, 0.3, 0.3])
B = np.dot(A, R)
print(B)[0.147975 0.1427875 0.1561625 0.1862875 0.1575375 0.20985 ]5 灰色关联分析(GRA)
灰色系统理论是1982年由邓聚龙创立的一门边缘性学科(interdisciplinary)。灰色系统用颜色深浅反映信息量的多少。一个系统是黑色系统,意为这个系统是黑洞洞的,信息量太少;一个系统是白色系统,意为这个系统是清楚的,信息量充足。而处于黑白之间的系统,或者说信息不完全的系统,称为灰色系统(简称灰系统)。
“信息不完全”一般指:
(1)系统因素不完全明确
(2)因素关系不完全清楚
(3)系统的结构不完全知道
(4)系统的作用原理不完全明了
关联分析即为系统地分析因素。其回答的问题为:某个包含多种因素的系统中,哪些因素是主要的,哪些是次要的;哪些因素影响大,哪些因素影响小;哪些因素是明显的,哪些因素是潜在的;哪些是需要发展的,哪些需要抑制……
现有因素分析的量化方法大都是数理统计法,如回归分析、方差分析、主要成分分析等,这些方法都有下述弱点:
(1)要求大量数据,数据量少难以找到统计规律。
(2)要求分布是典型的(线性的、指数的或对数的),即使是典型的也并非都能处理。
(3)计算工作量大,一般需要计算机帮助。
(4)有时可能出现反常情况,如正相关判断为负相关,以至正确现象受到歪曲和颠倒。
尤其是我国统计数据十分有限,而且现有数据灰度较大,许多数据都出现几次大起大落,没有典型的分布规律。因此,采用数理统计方法往往难以奏效。
5.1 基本概念
灰色关联分析(Grcy Rclation Analysis,GRA)是一种多因素统计分析的方法。该方法弥补了采用数理统计方法作系统分析所导致的缺憾。它对样本量的多少和样本有无规律都同样适用,而且计算量小,十分方便,更不会出现量化结果与定性分析结果不符的情况。
基本思想:根据序列曲线几何形状的相似程度来判断其联系是否紧密。曲线越接近,相应序列之间的关联度就越大,反之就越小。
对一个抽象的系统或现象进行分析,首先要选准反映系统行为特征的数据序列,称为找系统行为的映射量,用映射量来间接地表征系统行。例如,用国民平均接受教育的年数来反映教育发达程度,用刑事案件的发案率来反映社会治安面貌和社会秩序,用医院挂号次数来反映国民的健康水平等。有了系统行为特征数据和相关因素的数据,即可作出各个序列的图形,从直观上进行分析。
5.2 模型原理
5.2.1 定义母序列和子序列
首先需构造母子序列:
母序列(参考序列、母指标)为能反映系统行为特征的数据序列(类似于因变量),记为Y=[y_1,y_2,\cdots,y_n]^{\text{T}}
子序列(比较序列、子指标)为影响系统行为的因素组成的数据序列(类似于自变量),记为X_{nm}=(x_{ij})_{n\times m}
5.2.2 数据预处理
由于不同要素具有不同量纲和数据范围,因此要对其进行预处理去量纲,将其统一到近似的范围内。通常对数据进行均值化:先求出每个指标的均值,再用指标中的元素除以该均值(与之前的归一化不同)。
\tilde{y}_k=\frac{y_k}{\overline{y}_i},\ \overline{y}_i=\frac1n \sum\limits_{k=1}^{n}y_k\\
\tilde{x}_{ki}=\frac{x_{ki}}{\overline{x}_i},\ \overline{x}_i=\frac1n \sum\limits_{k=1}^{n}x_{ki}\ (i=1,2,\cdots,m)5.2.3 计算灰色关联系数
计算子序列中各个指标与母序列的关联系数。首先求母序列x_0与各子序列x_i的两极最小差和两极最大差(“最值中的最值”),分别记为
a=\min\limits_{i}\min\limits_{k}|x_0(k)-x_i(k)|\\
b=\max\limits_{i}\max\limits_{k}|x_0(k)-x_i(k)| 构造关联系数的公式,为
\xi_i(k)=y(x_0(k),x_i(k))=\frac{a+\rho b}{|x_0(k)-x_i(k)|+\rho b}其中\rho为分辨系数,一般取\rho=0.5。
5.2.4 关联度
最后求均值即可计算得关联度
r_i=\frac1n\sum\limits_{k=1}^{n}\xi_i(k)=\frac1n\sum\limits_{k=1}^n y(x_0(k), x_i(k))5.3 典型例题
5.3.1 例1:比较影响力(关联度)
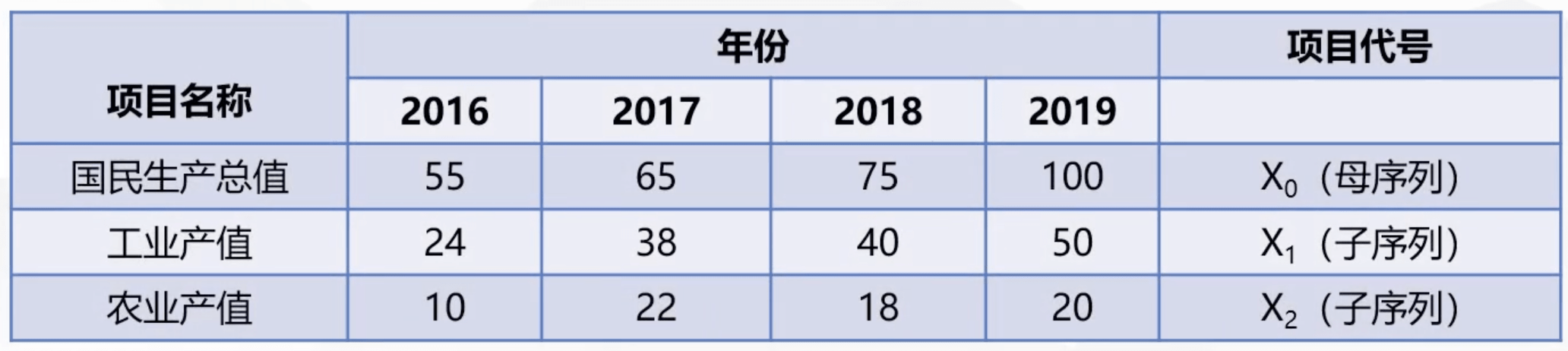
【例1】已知某地国民生产总值,工业和农业生产总值,原始数据的形式及来源见下表,分析工业、农业哪个对国民生产总值影响大

(1)定义母序列及子序列
(2)数据预处理/均值化

(3)求关联系数


(4)求关联度

r_1>r_2,故工业产值关联度更大。
5.3.2 例2:在综合评价问题中的运用(2.3变式)
【例2】将2.3 Python实现中的矩阵具象化为以下问题:使用TOPSIS法并结合灰色关联分析,给明星K选对象,有A、B、C三位候选人(K觉得身高165是最好,体重在90-100斤是最好)

(1)数据正向化处理(详见2.2.1)

(2)【新】数据预处理/均值化

(3)【新】构造母序列:评价决策问题中往往不存在明显的因变量,因此抽出每个对象所有指标的最大值组成母序列Y

(4)【新】计算关联系数

易得a=0,\ b=1.55,则关联系数如下表所示

(5)【新】计算关联度

(6)【新】计算指标权重:将关联度进行归一化(参考之前类似操作)后即为指标权重,如下表所示
w_i=\frac{r_i}{\sum\limits_{k=1}^m r_k}\ (i=1,2,\cdots,m)
(7)计算得分并归一化(详见2.2.3)

最后得出结论:B胜出!
5.4 Python实现
5.4.1 例1实现
import numpy as np
# 初始矩阵
A = np.array([[55, 24, 10], [65, 38, 22], [75, 40, 18], [100, 50, 20]])
print(f"A:\n{A}\n")
# 数据预处理:均值化
mean_A = np.mean(A, axis=0)
A_norm = A / mean_A
print(f"预处理后的矩阵:\n{A_norm}\n")
# 母序列
Y = A_norm[:, 0]
# 子序列
X = A_norm[:, 1:]
# 计算|母 - 子|矩阵
abs_Y_X = np.abs(X - np.tile(Y.reshape(-1, 1), (1, X.shape[1]))) # 注意调整Y的方向及形状
# 计算两极最小差和两极最大差
a = np.min(abs_Y_X)
b = np.max(abs_Y_X)
# 计算子序列中各个指标与母序列的关联系数(分辨系数取0.5)
rho = 0.5
xi = (a + rho * b) / (abs_Y_X + rho * b)
# 求关联度
r = np.mean(xi, axis=0)
print(f"子序列中各指标的灰色关联度分别为:\n{r}")A:
[[ 55 24 10]
[ 65 38 22]
[ 75 40 18]
[100 50 20]]
预处理后的矩阵:
[[0.74576271 0.63157895 0.57142857]
[0.88135593 1. 1.25714286]
[1.01694915 1.05263158 1.02857143]
[1.3559322 1.31578947 1.14285714]]
子序列中各指标的灰色关联度分别为:
[0.76966578 0.60058464]5.4.2 例2实现(2.3变式)
import numpy as np
# 参评对象、指标的个数
n = 3
m = 4
# 每个指标的类型,列表长度需为m(1:极大型,2:极小型,3:中间型,4:区间型)
kind = [1, 2, 3, 4]
# 矩阵,形状为(n, m)
A = np.array([9, 10, 175, 120, 8, 7, 164, 80, 6, 3, 157, 90]).reshape(n, m)
best_A = 165 # 若为中间型(类型3),还需设置最优值
low_A = 90 # 若为区间型(类型4),还需设置上下限
high_A = 100
print(A)[[ 9 10 175 120]
[ 8 7 164 80]
[ 6 3 157 90]]# 极小值指标转化为极大值指标
def min_to_max(x, max_x):
x = list(x) # 将输入的指标数据转换为列表
res = [[(max_x - e)] for e in x] # 计算最大值与每个指标元素的差
return np.array(res) # 将列表转换为numpy数组并返回
# 中间型指标转化为极大值指标
def mid_to_max(x, best_x):
x = list(x)
h = [abs(e - best_x) for e in x] # 计算每个指标元素与最优值的绝对差
M = max(h) # 找到最大的差值
if M == 0:
M = 1 # 防止最大差值为0的情况
res = [[1 - e / M] for e in h] # 计算每个差值占最大差值的比例,并从1中减去,得到新指标值
return np.array(res)
# 区间型指标转化为极大值指标
def reg_to_max(x, low_x, high_x):
x = list(x)
M = max(low_x - min(x), max(x) - high_x) # 计算指标值超出区间的最大距离
if M == 0:
M = 1 # 防止最大距离为0的情况
res = []
for i in range(len(x)):
if x[i] < low_x:
res.append([(1 - (low_x - x[i]) / M)]) # 如果指标值小于下限,则计算其与下限的距离比例
elif x[i] > high_x:
res.append([1 - (x[i] - high_x) / M]) # 如果指标值大于上限,则计算其与上限的距离比例
else:
res.append([1]) # 如果指标值在区间内,则直接取为1
return np.array(res)
# 统一指标类型,将所有指标转化为极大型指标
X = np.zeros((n, 1))
for i in range(m):
if kind[i] == 1:
v = np.array(A[:, i])
elif kind[i] == 2:
max_A = max(A[:, i])
v = min_to_max(A[:, i], max_A)
elif kind[i] == 3:
v = mid_to_max(A[:, i], best_A)
else:
v = reg_to_max(A[:, i], low_A, high_A)
if i == 0:
X = v.reshape(-1, 1) # 若为第1个指标,直接替换X数组
else:
X = np.hstack([X, v.reshape(-1, 1)]) # 若非第1个指标,则将该指标列拼接到X数组上
print("统一指标后的矩阵为:\n{}".format(X)) # 打印处理后的矩阵X统一指标后的矩阵为:
[[9. 0. 0. 0. ]
[8. 3. 0.9 0.5]
[6. 7. 0.2 1. ]]以下为新操作
# 对正向化后的矩阵进行预处理/均值化
mean_X = np.mean(X, axis=0)
Z = X / mean_X
print(f"预处理后的矩阵为:\n{Z}")预处理后的矩阵为:
[[1.17391304 0. 0. 0. ]
[1.04347826 0.9 2.45454545 1. ]
[0.7826087 2.1 0.54545455 2. ]]# 构造母序列和子序列
Y = np.max(Z, axis=1) # 母序列为虚拟的,用每一行的最大值构成的列向量表示母序列
X = Z # 子序列即为预处理后的数据矩阵# 计算得分系列操作
abs_Y_X = np.abs(X - np.tile(Y.reshape(-1, 1), (1, X.shape[1]))) # 注意调整Y的方向及形状
a = np.min(abs_Y_X)
b = np.max(abs_Y_X)
rho = 0.5 # 分辨系数取0.5
xi = (a + rho * b) / (abs_Y_X + rho * b) # 计算关联系数
weights = np.mean(xi, axis=0) / np.sum(np.mean(xi, axis=0)) # 利用子序列中各个指标的灰色关联度计算权重
scores = np.sum(X + np.tile(weights, (X.shape[0], 1)), axis=1) # 未归一化的得分
stand_s = scores / np.sum(scores) # 归一化后的得分
sorted_s = np.sort(stand_s)[::-1] # 进行降序排序
indices = np.argsort(stand_s)[::-1] # 排序后的索引
print("归一化后的得分及其索引(降序):")
print(sorted_s)
print(indices)归一化后的得分及其索引(降序):
[0.42853755 0.42653491 0.14492754]
[2 1 0]6 主成分分析(PCA)
在分析研究多变量的课题时,变量太多就会增加课题的复杂性,人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间有一定的相关关系,可以解释为这两个变量反映此课题的信息有一定的重叠。
6.1 基本概念
主成分分析(PCA)对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去,建立尽可能少的新变量,使得这些新变量两两不相关,且这些新变量在反映课题的信息方面尽可能保持原有的信息。设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要可以从中取出几个较少的综合变量,尽可能多地反映原来变量的信息。这种统计方法即为主成分分析(主分量分析),也是数学上用来降维的一种方法。
降维是将高维度的数据(指标太多)保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内可以节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维具有如下一些优点:
- 使得数据集更易使用
- 除噪声
- 降低算法的计算开销
- 使得结果容易理解

PCA是一种线性降维方法,即通过某个投影矩阵将高维空间中的原始样本点线性投影到低维空间,以达到降维的目的,线性投影就是通过矩阵变换的方式把数据映射到最合适的方向。
降维的几何意义可以理解为旋转坐标系,取前k个轴作为新特征。
降维的代数意义可以理解为m\times n阶的原始样本X,与n\times k阶矩阵W做矩阵乘法运算X\times W,即得到m\times k阶低维矩阵Y,这里的n\times k阶矩阵W就是投影矩阵。
主成分分析的理论推导较为复杂,需要借助投影寻踪,构造目标函数等方法来推导,在多元统计的相关书籍中都有详细讲解。但是其结论却是十分简洁。所以,如果只是需要实际应用,了解主成分分析的基本原理与实现方法便足够了。
6.2 模型原理
设有n个样本、p个指标,则可构成大小为n\times p的样本矩阵x=(x_{ij})_{n\times p}=(x_1,x_2,\cdots,x_p)。假设想找到一组新变量z_1,z_2,\cdots,z_m\ (m≤p),且满足
\left\{\begin{matrix}
z_1=l_{11}x_1+l_{12}x_2+\cdots+l_{1p}x_p \\
z_2=l_{21}x_1+l_{22}x_2+\cdots+l_{2p}x_p \\
\vdots \\
z_m=l_{m1}x_1+l_{m2}x_2+\cdots+l_{mp}x_p
\end{matrix}\right.系数l_{ij}的确定原则:
(1)z_i与z_j\ (i≠j;\ i,j=1,2,\cdots,m)相互无关
(2)z_1是与x_1,x_2,\cdots,x_p的一切线性组合中方差最大值
(3)z_2是与z_1不相关的x_1,x_2,\cdots,x_p的一切线性组合中方差最大者
(4)以此类推,z_m是与z_1,z_2,\cdots,z_{m-1}不相关的x_1,x_2,\cdots,x_p的所有线性组合中方差最大者
(5)新变量指标z_1,z_2,\cdots,z_m分别称为原变量指标x_1,x_2,\cdots,x_p的第1、第2、…… 、第m主成分
6.2.1 标准化
按列计算均值
\overline{x}_j=\frac1n\sum\limits_{i=1}^n x_{ij}标准差
S_j=\sqrt{\frac{\sum\limits_{i=1}^n(x_{ij}-\overline{x}_j)^2}{n-1}}计算得标准化数据
X_{ij}=\frac{x_{ij}-\overline{x}_j}{S_j}原始样本矩阵经过标准化变为X=(X_{ij})_{n\times p}=(X_1,X_2,\cdots,X_p)
6.2.2 计算样本相关系数矩阵
计算样本相关系数矩阵(协方差矩阵)R=(r_{ij})_{n\times p},其中
r_{ij}=\frac1{n-1}\sum\limits_{k=1}^n(X_{ki}-\overline{X}_i)(X_{kj}-\overline{X}_j)6.2.3 计算特征值和特征向量
计算R的特征值和特征向量
特征值:\lambda_1≥\lambda_2≥\cdots≥\lambda_p≥0
特征向量:a_1=[a_{11}, a_{21}, \cdots,a_{p1}]^\text{T},\cdots,a_p=[a_{1p},a_{2p},\cdots,a_{pp}]^\text{T}
6.2.4 计算贡献率
计算主成分贡献率
\alpha_i=\frac{\lambda_i}{\sum\limits_{k=1}^p\lambda_k}\ (i=1,2,\cdots,p)以及累计贡献率
\sum G=\frac{\sum\limits_{k=1}^i\lambda_k}{\sum\limits_{k=1}^p\lambda_k}\ (i=1,2,\cdots,p)贡献率能够体现原始的信息。
6.2.5 写出主成分并分析
一般取累计贡献率超过80%的特征值所对应的第1、第2、…… 、第m\ (m≤p)个主成分。第i个主成分为
F_i=a_{1i}X_i+a_{2i}X_2+\cdots+a_{pi}X_p\ (i=1,2,\cdots,m)对于某个主成分而言,指标前面的系数越大,代表该指标对于该主成分的影响越大。
利用主成分的结果进行后续的分析:
- 主成分得分
- 聚类分析
- 回归分析
6.3 典型例题
6.3.1 例1:选取主成分
【例1】在制定服装标准的过程中,对128名成年男子的身材进行了测量,每人测得的指标中含有以下六项:身高(x_1)、坐高(x_2)、胸围(x_3)、手臂长(x_4)、肋围(x_5)、腰围(x_6)。所得的样本相关系数矩阵(对称矩阵)如下表所示

此处直接给出样本相关系数矩阵,实际应对原始数据进行标准化后自行根据定义计算得出。
(1)计算特征值和特征向量、贡献率如下表所示。由表可知,前3个主成分的累计贡献率达85.9%,因此可考虑只取3个主成分,它们足够很好地概括原始变量。

(2)写出主成分并分析解释含义
前3个主成分如下所示(其中X_i均为标准化后的指标,x_i定义见题干)
F_1=0.469X_1+0.404X_2+0.394X_3+0.408X_4+0.339X_5+0.427X_6
F_2=-0.365X_1-0.397X_2+0.397X_3-0.365X_4+0.569X_5+0.308X_6
F_2=0.092X_1+0.613X_2-0.279X_3-0.705X_4+0.164X_5+0.119X_6
i. 第1主成分F_1对所有(标准化)原始变量都有近似相等的正载荷,故称第1主成分为大小成分
ii. 第2主成分F_2在X_3,X_5,X_6上有中等程度的正载荷,而在X_1,X_2,X_4上有中等程度的负载荷,故称第2主成分为形状成分(或胖瘦成分)
iii. 第3主成分F_3在X_2上有较大的正载荷,在X_4上有较大的负载荷,而在其余变量上的载荷都较小,可称第3主成分为臂长成分。当然,由于第3主成分贡献率不算高,实际意义也不太重要,因此可以考虑只取前两个。
6.3.2 例2:探究多指标关系
探究棉花单产和五个指标之间的关系(解题过程见6.4 Python实现)

参照上述解法可得

从结果中可以看出,前两个主成分累计贡献率为97.74%
i. 第1主成分F_1在所有变量上都有近似相等的正荷载,反映了在种植投入上较为综合的水平,因此第1主成分可称为综合投入成分。
ii. 第2主成分F_2在变量农药上有很高的的负荷载,而在其余变量上均为正荷载,可以认为这个主成分度量了受土壤环境影响的投入在所有投入中的占比。
在主成分分析中,首先应保证所提取的前几个主成分的累计贡献率达到一个较高的水平,其次对这些被提取的主成分必须都能够给出符合实际背景和意义的解释。
主成分的解释其含义一般多少带有点模糊性,不像原始变量的含义那么清楚、确切,这是变量降维过程中不得不付出的代价。因此,提取的主成分个数m通常应明显小于原始变量个数p(除非p本身较小),否则维数降低的“利”可能抵不过主成分含义不如原始变量清楚的“弊”。
如果原始变量之间具有较高的相关性,则前面少数几个主成分的累计贡献率通常就能达到一个较高水平,也就是说,此时的累计贡献率通常较易得到满足。
主成分分析的困难之处主要在于要能够给出主成分的较好解释,所提取的主成分中如有一个主成分解释不了,整个主成分分析也就失败了。
主成分分析是变量降维的一种重要、常用的方法,简单的说,该方法要应用得成功,一是靠原始变量的合理选取,二是靠“运气”。
——参考教材:《应用多元统计分析》王学民
因此在进行主成分分析之后,通常采用其他评价决策方法进行正式分析操作。
6.4 Python实现
6.3.2【例2】实现
import numpy as np
import pandas as pd
# 读取Excel文件的B:G列,去除第1行(标题)
df = pd.read_excel("棉花产量数据.xlsx", usecols="C:G")
print(df)
# 转换为numpy数组
x = df.to_numpy()
print(x)
# 标准化数据
X = (x - np.mean(x, axis=0)) / np.std(x, ddof=1, axis=0)
# 使用np.cov()计算协方差矩阵/样本相关系数矩阵
R = np.cov(X.T) # X应转置
# 计算特征值和特征向量
eig_values, eig_vectors = np.linalg.eig(R)
# 将特征值数据按降序排列
eig_values = eig_values[::-1]
# 将特征值向量矩阵的列按降序排列
eig_vectors = eig_vectors[:, ::-1]
# 计算主成分贡献率和累积贡献率
contribution_rate = eig_values / sum(eig_values)
cum_contribution_rate = np.cumsum(contribution_rate) # np.cumsum()累计求和
print(f"特征值为:\n{eig_values}")
print(f"贡献率为:\n{contribution_rate}")
print(f"累计贡献率为:\n{cum_contribution_rate}")
print(f"与特征值对应的特征向量矩阵为:\n{eig_vectors}")